
ドーモ、今回は自分が普段から使用しているwan2.1のimage to videoのワークフローをcivitaiにて公開したのですが、おそらくパッと見た感じだと使い方がよくわからないと思います、ですが内容が分かればすごく利便性の高いワークフローなのでwan2.1を使い始めたばかりの方にもわかりやすいように基本的な簡単な説明を交えながらグループ毎に詳しく説明していきたいと思います!(下にリンクを貼っておきます)
Wan2.1 img2vid workflow – v1.0 | Wan Video Workflows | Civitai
model
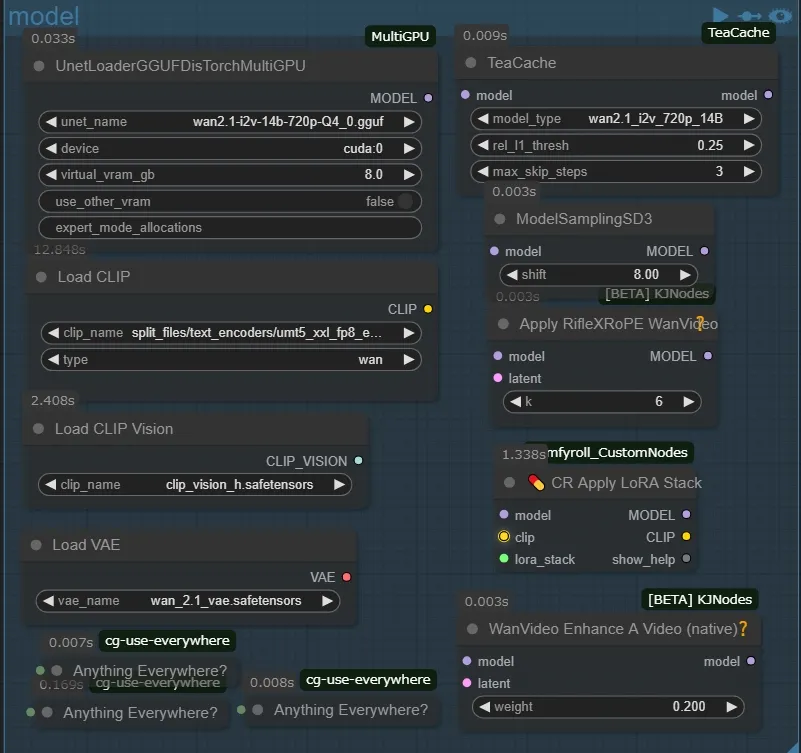
modelグループは普段ほとんどいじってないですね、左上のノードは量子化モデルを読み込むためのノードです、deviceはモデルの読み込み先をcpuかgpuかを選べますがcpuにする意義はほぼ無いと言っても等しいので複数のgpuがある人向けの設定です、virtual_vram_gbは本来vramに読み込ませるモデルをこれで指定した分だけramに読み込ませます(例えば10GBのモデルなら8.0に設定した場合2GB分をvramで読み込み、8GB分ramで読み込みます)このおかげで低VRAMでも使用できるのですが普通はその場合、処理に時間がかかって生成時間が延びてしまいます、ですがこれにはDisTorchという機能が付いています、これのおかげでいくらRAMに割り当てても、生成時間は変わらず使用することが出来ます、virtual_vramに一切割り当ててない状態と10GB割り当てた状態で一度比べてみたのですが全く速度に変化がありませんでした(スゴイデスネ!)因みにLoad Clipにも同様のノードがあるのでramが潤沢な人はそちらに差し替えてもいいかもしれません
・Teacacheノードは砕けて説明すると、生成後半の不必要な処理をスキップして高速化するためのものです(大体30~40%ほど短縮されます、モデルごとにそれぞれ適切な数値があるので公式の表を参考にしてください、・RifleXRoPEノードはビデオの最大秒数を拡張するためのものです、Wan2.1で推奨されている最大秒数は81フレーム…つまり5秒です、それを超えると破綻などが起きてくるわけですね、その秒数を最大で5秒から8秒にしてくれるのがこのノードです、その下の・💊 CR Apply LoRA StackノードですがWan2,1でloraを適用するのにclipは必要ありませんが入力に接続しないとエラーが起きるので入力だけ繋いでmodelだけ出力しています、これで問題なく使用できるのでおすすめです、・WanVideo Enhance A Videoノードはリアリスティックな動画をより現実的なものにする効果があるようですが、自分はイラスト系の動画ばかり生成しているので、これに関してはあまり良くわかってないです、ただ入れといて損はないかなぁという感じでいれています
モデルのダウンロード、配置場所
※ggufモデルは
city96/Wan2.1-I2V-14B-720P-gguf
city96/Wan2.1-I2V-14B-480P-gguf ComfyUI/models/unet
Comfy-Org/Wan_2.1_ComfyUI_repackagedの split_files/clip_vision/clip_vision_h.safetensors ComfyUI/models/clip_vision
split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors ComfyUI/models/clip ←(ここは人によっては違う?自分はこのフォルダでした)
split_files/vae/wan_2.1_vae.safetensors ComfyUI/models/vae
Lora

Loraグループでは3つのloraを1ボタンでそれぞれバイパスするようにしました、最初はLoRA Stackノード一つで複数のLoraを使えるようにしようと思っていたのですが、それだと不都合が出たのでこの形式にしました、これでLoraをオンにするだけでcivitaiからtriggerWordを自動的に読み込んでプロンプトに追記してくれます、また使用したtriggerWordとlora_weightをファイル名に追記します(モデル名では長すぎるのでtriggerWordを追記するようにしました)ひとつ注意点がありましてこのグループをミュートにするとエラーが発生しますのでオフにするときは必ずバイパスするようにしてください
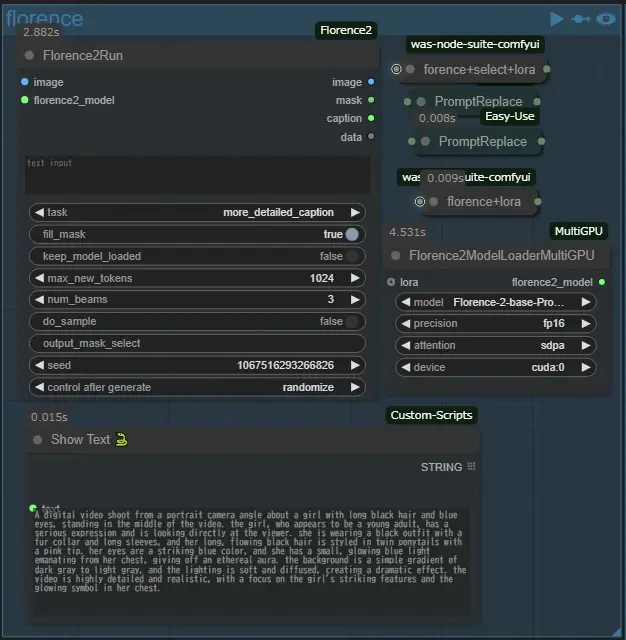
image&プロンプト
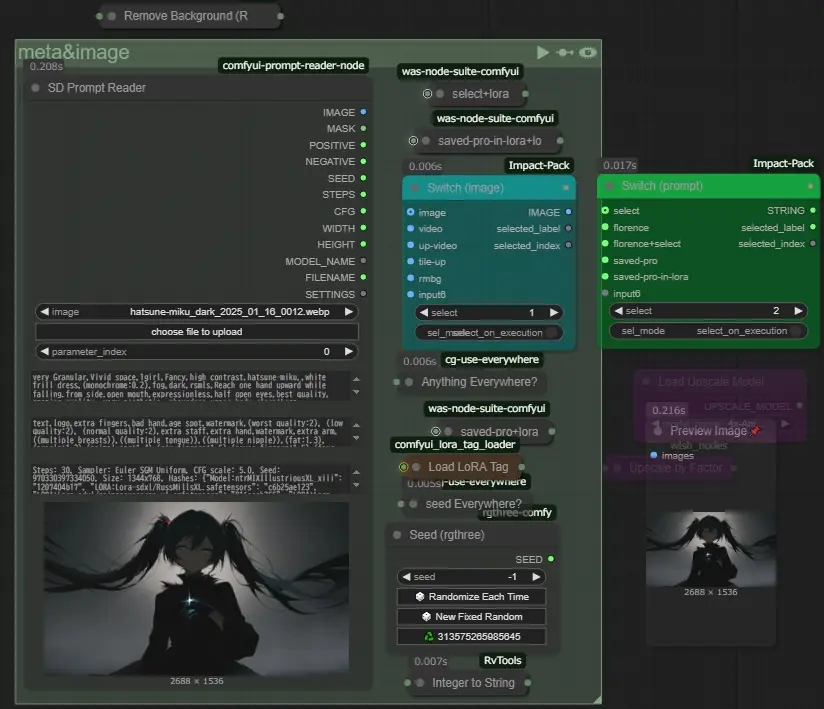
SD Prompt Readerを使用して画像に保存されたプロンプトを読み込み、ファイル名を生成した動画に流用、シード値も文字列に変換してファイル名に追記しますSwitch (image)では使用する画像を選びます。imageは左のノードから、videoは後述するvideo-pathグループから最後の1フレームを自動で抜き出して使用します、up-videoはvideoの物と同じ画像をアップスケールを行ってから使用します、tile-upはtileコントロールネットなどを使って画像を再描画してから使用します
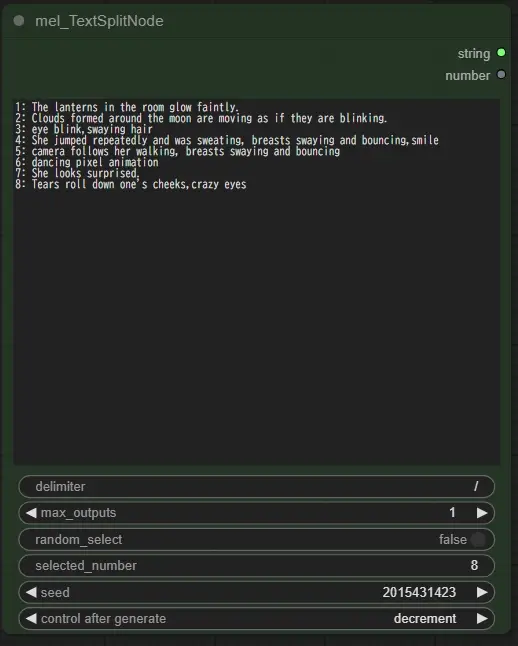
Switch (prompt)で使用するプロンプトを選択します、どれを選んでもloraが適用されている場合はtriggerWordが追記されます、selectは上のmel_TextSplitNodeから選んだものをプロンプトに使用します、florenceは下のfrorence2を使用して画像から生成したプロンプトを使用しますモデルは下記からダウンロードしてComfyUI/models/LLMにフォルダを配置してください、florence+selectは両方のプロンプトを適用します、saved-proは画像に保存されたプロンプトのlora情報を除外して使用します、Load LoRA Tagを通しているのはそのためです、逆にsaved-pro-in-loraはそのまま使用します、これはlora情報が動画に面白い結果を与えることがあったため残しました
MiaoshouAI/Florence-2-base-PromptGen-v2.0 · Hugging Face 約3.3G もしくは
MiaoshouAI/Florence-2-base-PromptGen-v2.0 · Hugging Face 約1.1G 計量版
main
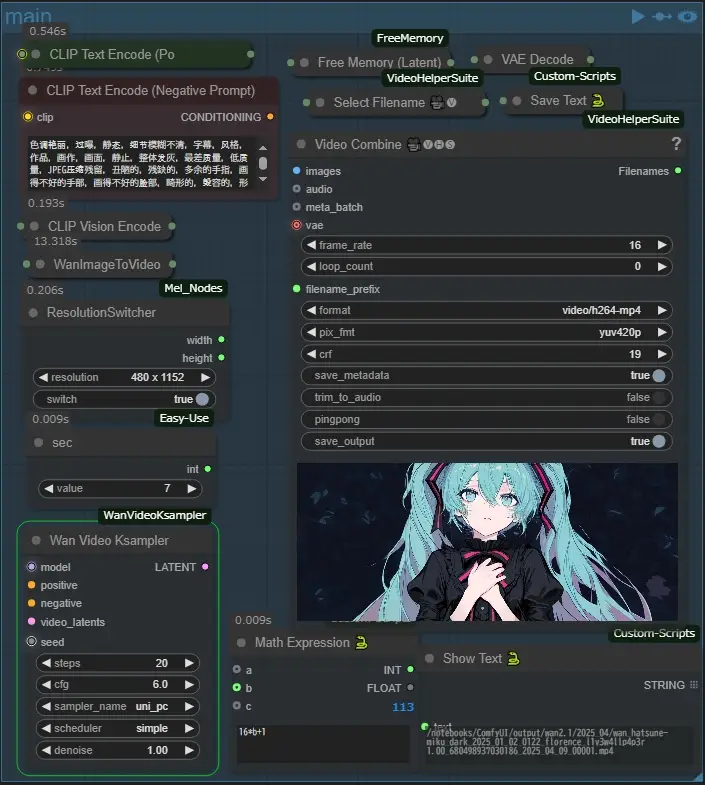
mainのグループでは主に操作するノードは2つだけです、1つはResolutionSwitcher、これで動画の解像度を適切な任意の解像度に即座に変えられます、またsecノードは動画の秒数を変更するのに使用します、wan2.1では16+1フレームを1秒として生成します(33で2秒、49で3秒です)Math Expressionノードによってその計算を行っているので、secノードの値がそのまま秒数になっています、また私のワークフローでは動画の出力名をテキストファイルに保存して他のグループで使用しています(デフォルトのファイルネームはwanvideo.txtです)、これでそれぞれのグループをスタンドアロンで使用する時、ファイルパスの入力の手間を軽減しています、(最初に生成する場合、これより下のグループを使用する時エラーが出るかもなので一度これで生成してから使用するのをおすすめします)
upscale
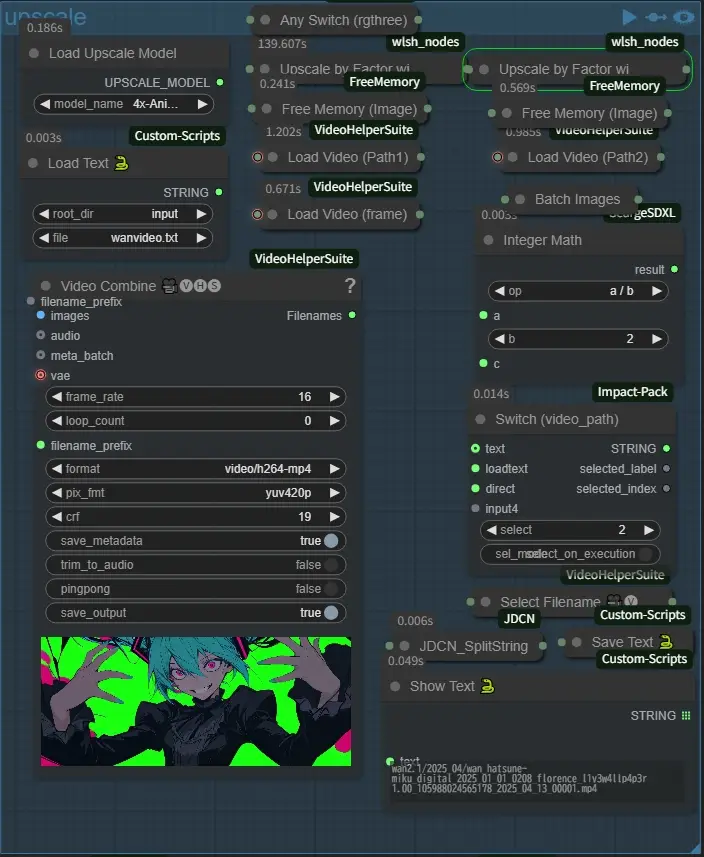
upscaleグループでアップスケールを行いますSwitch (video_path)でアップスケールする動画が格納されているディレクトリのfullpathを選択します、textは上の範囲外にあるテキストボックスに入力したものを使用し、loadtextは左上のLoad Text 🐍でテキスト保存されたものを使用します、またアップスケールの際、動画を半分ずつ2回に分けて行うようにしています、これは自分の環境ではよくこの工程でComfyUIが停止することがままあるのでこれで処理を軽減させています、推察ですが固まったときはよくRAMが99%になって固まっていたのでRAM不足が原因だと思います、おそらく64Gとかある人は大丈夫なんでしょうけど45Gでは一度に処理しようとするとギリギリって感じです、最初の説明でモデルをRAMに読み込ませるノードがありましたね、おそらく割り当てすぎるとRAMが心許ない方はここの処理の途中で停止する可能性が高くなるので気をつけてください 出力名のデフォルト:upscale.txt
video-path
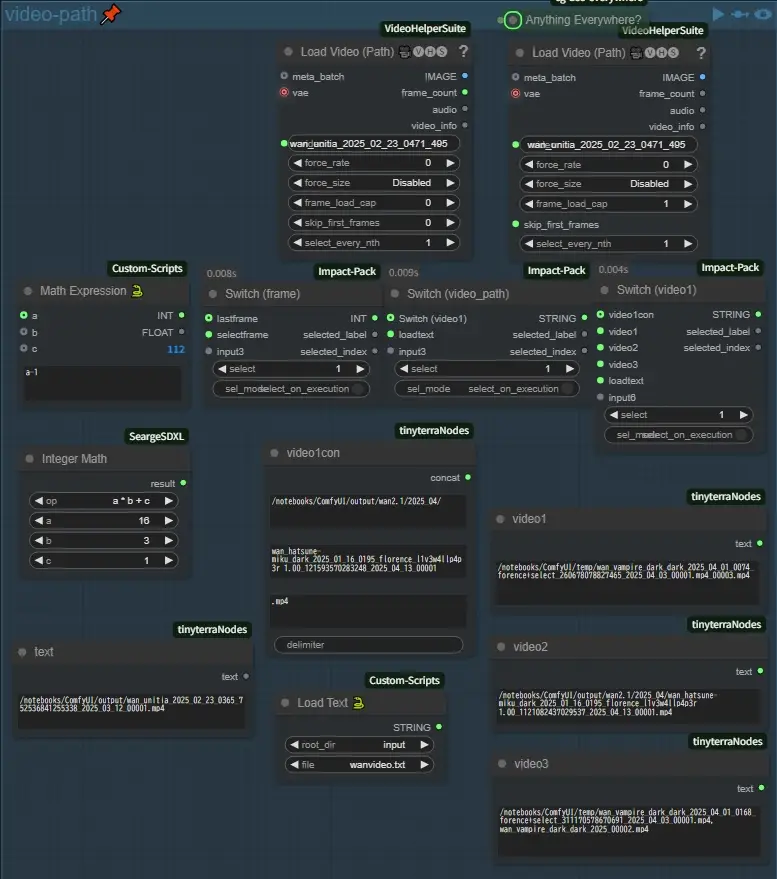
このグループではSwitch (image)で使用する動画の読み込みや、次に説明するvideo-joinグループで使用する動画のパスを指定します、例によってloadvideoが二つありますが左の方はフレーム数を読み込んで最後の1フレームを計算するために使用しています、Switch (frame)で一応使用するフレームを変更できるようにしています、Switch (video_path)で生成に使用する動画のパスを右のSwitch (video1)で選択した次のグループで使用する一つ目の動画のパスを選択します
結合
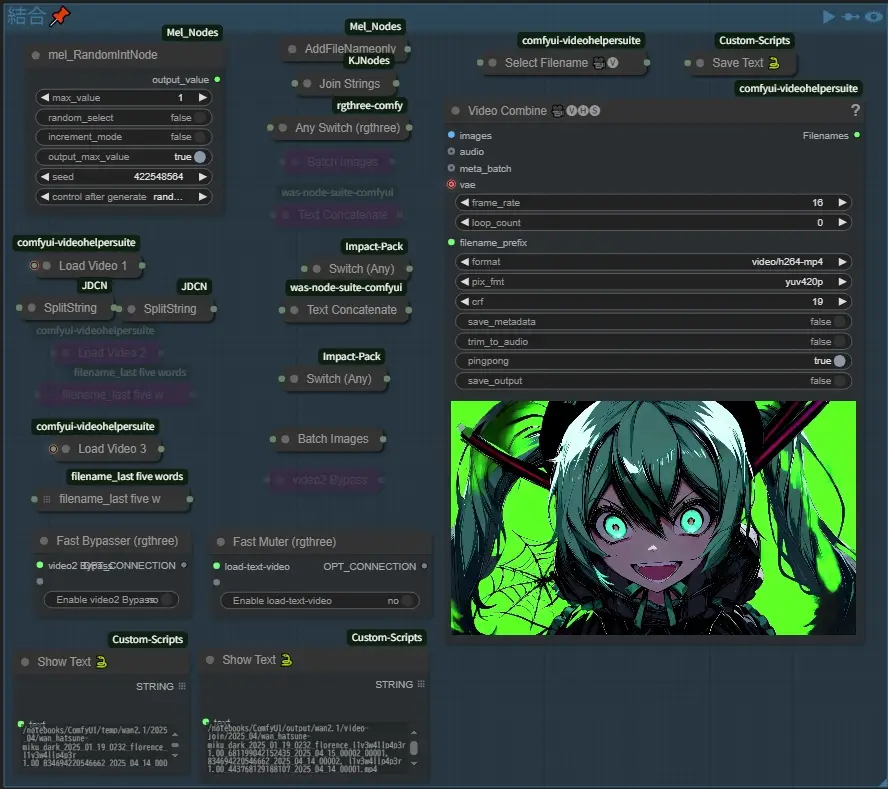
このグループで動画の結合などを行います、左上のINTは1で2つ、2で3つの動画を使用するようにします、出力名は使用した動画のファイルネームを全て入力しようとしたら長すぎてerrorが出たので、2つ目からは末尾の_で分割された5語を入れることにしました(自分は何度も試行したりするのでここから下のグループはsave_outputが最初falseになっています、保存しておきたい人は気をつけてください)また同じ画像から生成した2つの動画を簡単に繋げられるようにしています、手順を説明しますと、まず上の画像の様にFast BypasserとFast Muterで接続されているものをOFFにします、そしてVideo Combineのpingpongをtrueにしてこのグループのキューを押します、 出力名のデフォルト:video-join.txt
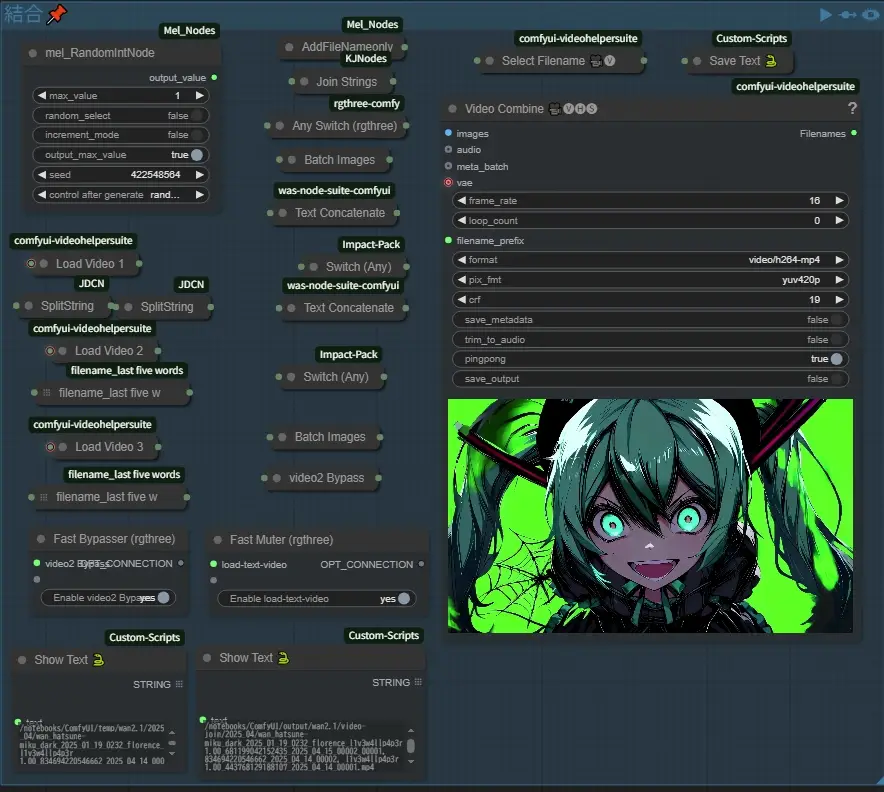
次にFast BypasserとFast MuterをONにして再びグループのキューを押します(pingpongは綺麗にループしそうだったらONのままでもいいです)
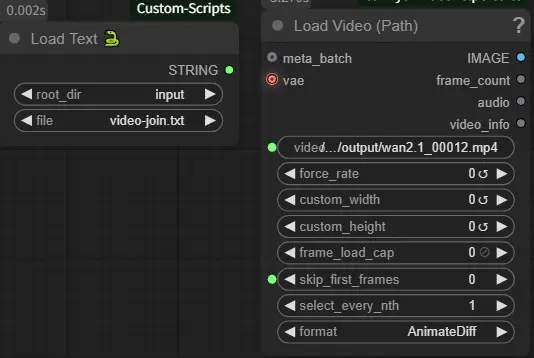
これで終わりです、2つの動画が綺麗に繋がったと思います、このグループの左下に上の画像のノードがあると思いますが、Fast Muterで繋げているものです、video1のフレーム分をそのままスキップするようにしているので、後ろ半分だけが使われるようになっています(ただ動画のフォーマットによるものかわからないんですが、Video Combineを繰り返していると色味が若干変化していくんですよね…これはちょっと思考中です)
film1,film2
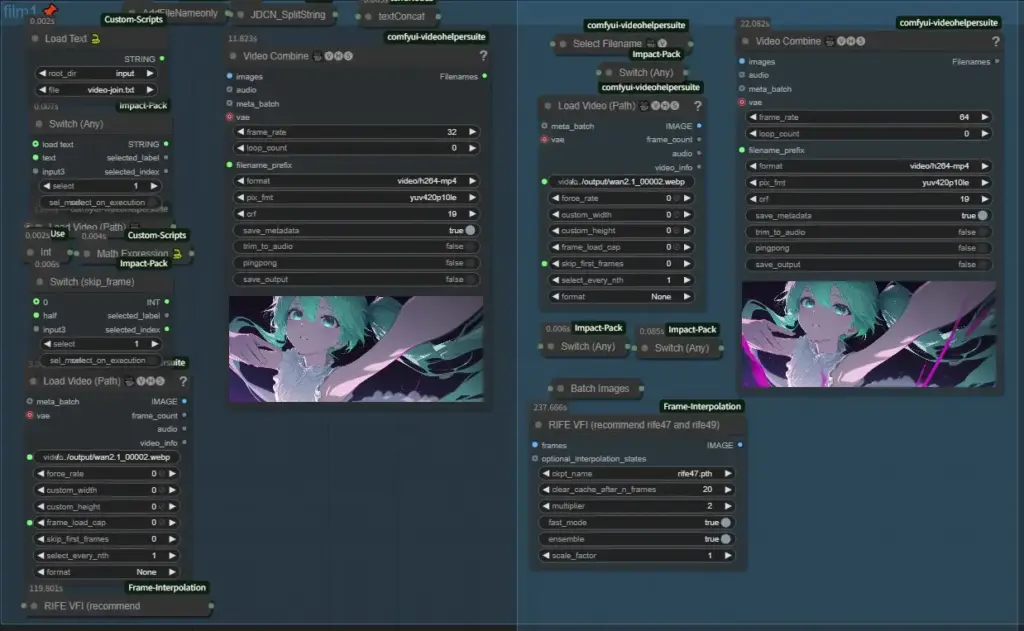
このグループではフレーム補間を行い動画のfpsを32、または64fpsに変換します、まずfilm1でfpsを32にしてfilm2で64にする形です、32で十分な場合はfilm2をミュートにして実行してくださいまた、Switch (skip_frame)が1の時は普通ですが2の時は一つの動画をfilm1とfilm2で半分ずつ処理を行います、アウトオブメモリなどが出た場合などに使って下さい
画像の再生成
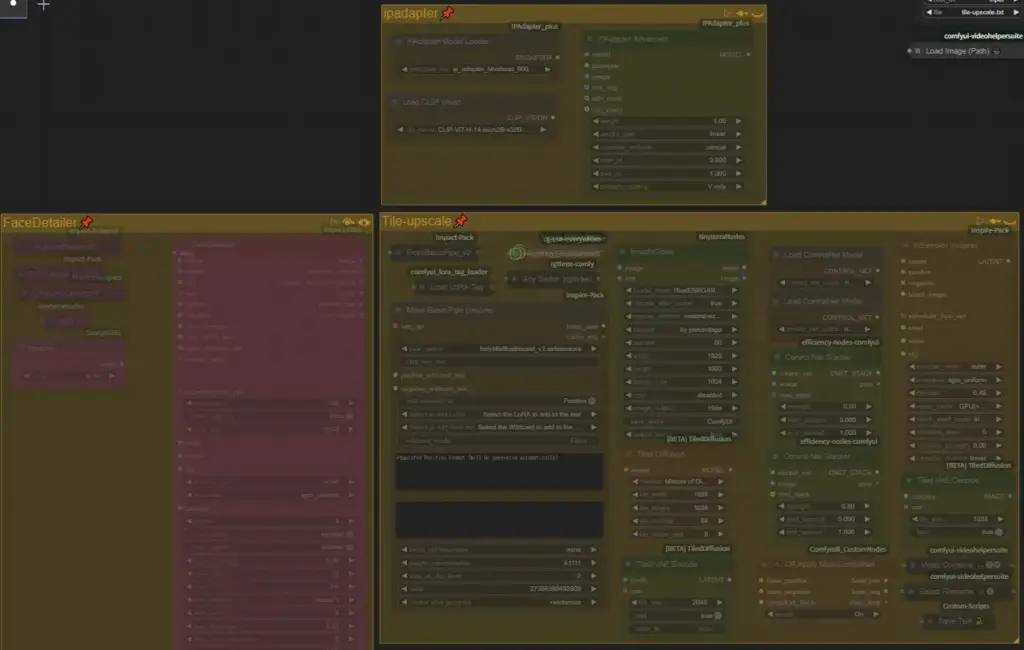
ipadapterとtileコントロールネットなどを使用して元の画像の構成を維持したまま再生成を行い、ぼやけた画像をクリアにするのに使用します、FaceDetailerはほとんど使ってないので削除してもらってもかまいません(画像のメタデータを使用するようになっています)
pixel
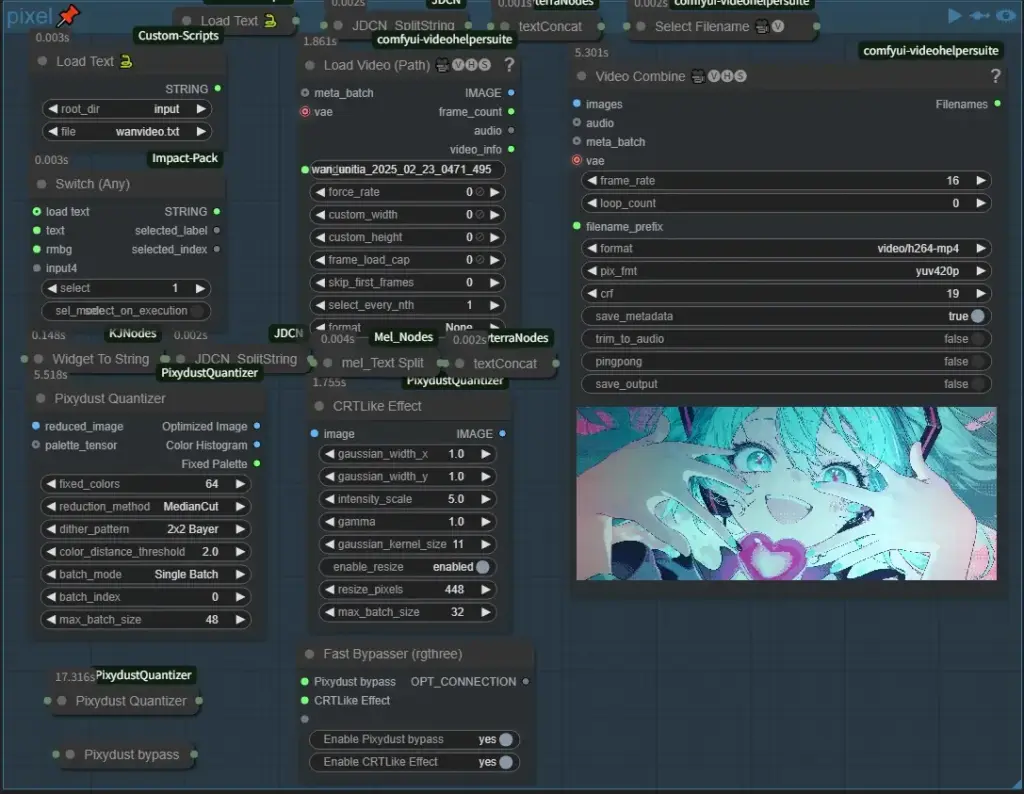
このグループではHiroさんのComfyUI-PixydustQuantizerカスタムノードを用いて動画をまるでレトロゲーム風や精微なピクセルアニメーションのように変化させることが出来ます、このカスタムノードは誇張なしで素晴らしいです!この独特の雰囲気が好きな人にはたまらないです、設定を少し変えるだけでかなりの変化が出るのでいろいろ試しているだけで面白いですよ!説明が長くなりそうなのでそれぞれの設定の詳しい効果は別の機会に書こうと思いますが、一つ懸念がありまして、これは自分の環境のせいなのかわからないんですけど最初、numpy関連のエラーが出たんですよね…、もし自分と同じエラーが出た場合はpixydust_quantizer.pyの114行目に次のコードを追記してください
# ヒストグラム配列の形状を統一するヘルパー関数
def resize_array(arr, target_shape):
# まず切り詰め(targetより大きい場合)
slices = tuple(slice(0, min(s, t)) for s, t in zip(arr.shape, target_shape))
resized = arr[slices]
# 不足している場合はゼロでパディング
pad_width = []
for current, target in zip(resized.shape, target_shape):
pad_width.append((0, target - current))
resized = np.pad(resized, pad_width, mode='constant', constant_values=0)
return resized
# 最初のヒストグラムの形状を基準に各ヒストグラムを調整
if histogram_images:
target_shape = histogram_images[0].shape
histogram_images = [
resize_array(hist, target_shape) if hist.shape != target_shape else hist
for hist in histogram_images
]
これでエラーはなくなるはずです、もし自分と同じエラーが出た人がいたらコメント等で教えてほしいです、プルリクエストを送った方がいいのかわからないので、
以上で終わりです、このワークフローは自分は使用した情報は出来るだけ生成したものに残しておきたい、そして生成の手間をなるべく減らしたい……そのための手間は惜しまない!という自己矛盾のもとで作成しておりました、もっと早く公開したかったのですが、ブログをはじめて間もないのでこのページを作るのにめっちゃ時間かかっちゃいました…、もし質問とかこうした方がいいとかありましたらぜひ教えてください!また何か追加したら追記すると思います、ではまた!


コメント